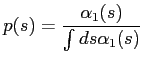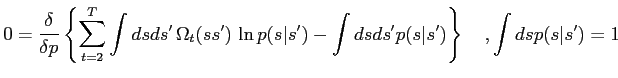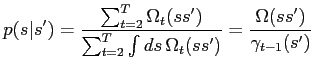The three terms that need to be maximised in the E-step are
The maximisation of (M1) is achieved by
The maximisation of (M2) is
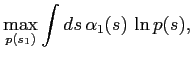
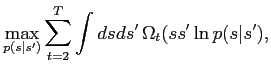
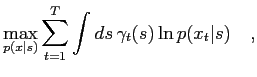
![$\displaystyle 0 = \frac{\delta}{\delta p} \left\{\int ds \, \alpha_1(s) \, \ln p(s) - \lambda\left[\int ds p(s) -1 \right] \right\},\quad \int ds p(s) = 1$](img109.png)